�� ���Ƶ��ھ��� �����ҡ�û����ꡱ������DNA/RNA����Watson��������
��

���ߣ����չ�
�����ϵ���ͳ����ѧ��ʼ��
��ҽҩ���������й�����ϯ
���绪�˱����ܱ�
һ����ɭ����Watson��s Table������������״
����
��DNA֮������ɭ��Watson���ų�Ů�Կ�ѧ����ɯ�յ¡��������ֶ�DNA˫�����ṹ�Ĺ��ף���ͬ����ˣ�Crick����ͬ�����ŵ�������������ڱ�������ɯ�յ������ǣ�Ҳ�������ԭ����˾����������ˣ�����227����Ԫ��������ŵ�������£�������ɭ���������480����Ԫ����˵ǰһ����һλ�й������ĵã���һ���ɶ���˹�ĸ����ĵã���֧����ɭ�Ŀ��й�������֮����ŵ���������õ����ǵ����͡�����������������ɭ�������˵��о��ɹ������ɵ�һ���й�DNA�����ּ���Ͷ�ʮ�ְ�����֮��ƥ��Ĺ�ϵ�������˰����ű���֮Ϊ����ɭ������ Watson's Table,����1����
��
��1 DNA���ּ�����ʮ�ְ�����֮���ϵ��ʵ���ܽ��
|
��һλ��5��ˣ� ������ |
�ڶ�λ���м䣩������ |
����λ��3��ˣ� ������ |
|||
|
U |
C |
A |
G |
||
|
U |
�������ᣨPhe,F�� |
˿���� ��Ser,S�� |
�Ұ��� ��Tyr,Y�� |
���װ��ᣨCys,C�� |
U |
|
�������ᣨPhe,F�� |
˿���� ��Ser,S�� |
�Ұ��� ��Tyr,Y�� |
���װ��ᣨCys,C�� |
C |
|
|
������ ��Leu,L�� |
˿���� ��Ser,S�� |
��ֹ ��Stop�� |
��ֹ ��Stop�� |
A |
|
|
������ ��Leu,L�� |
˿���� ��Ser,S�� |
��ֹ ��Stop�� |
ɫ���� ��Trp,W�� |
G |
|
|
C |
������ ��Leu,L�� |
������ ��Pro,P�� |
�鰱�� ��His,H�� |
������ ��Arg,R�� |
U |
|
������ ��Leu,L�� |
������ ��Pro,P�� |
�鰱�� ��His,H�� |
������ ��Arg,R�� |
C |
|
|
������ ��Leu,L�� |
������ ��Pro,P�� |
�Ȱ����� ��Gln,Q�� |
������ ��Arg,R�� |
A |
|
|
������ ��Leu,L�� |
������ ��Pro,P�� |
�Ȱ����� ��Gln,Q�� |
������ ��Arg,R�� |
G |
|
|
A |
�������ᣨIle,I�� |
�հ��� (Thr,T) |
�춬������Asn,N�� |
˿���� ��Ser,S�� |
U |
|
�������ᣨIle,I�� |
�հ��� (Thr,T) |
�춬������Asn,N�� |
˿���� ��Ser,S�� |
C |
|
|
�������ᣨIle,I�� |
�հ��� (Thr,T) |
������ ��Lys,K�� |
������ ��Arg,R�� |
A |
|
|
�����ᣨMet,M�� |
�հ��� (Thr,T) |
������ ��Lys,K�� |
������ ��Arg,R�� |
G |
|
|
G |
�Ӱ��� ��Val,V�� |
������ (Ala,A) |
�춬���� ��Asp,D�� |
�ʰ��� ��Gly,G�� |
U |
|
�Ӱ��� ��Val,V�� |
������ (Ala,A) |
�춬���� ��Asp,D�� |
�ʰ��� ��Gly,G�� |
C |
|
|
�Ӱ��� ��Val,V�� |
������ (Ala,A) |
�Ȱ��� ��Glu,E�� |
�ʰ��� ��Gly,G�� |
A |
|
|
�Ӱ��� ��Val,V�� |
������ (Ala,A) |
�Ȱ��� ��Glu,E�� |
�ʰ��� ��Gly,G�� |
G |
|
��
���������п��Կ�����һȺ���������������������е����ļ���ṹ�����еĹ�ϵ�����˰����ű�˵�ɿ����Ž��з�Ԫ�����ڱ��ķ���������[1]������������Ҳ�ڷ���˵���ǡ�û����ꡱ��һ�ű�����ΪWatsonֻ�������������˵ijɹ���������û�����Ϊʲôһ���������DNA�����64�������ӣ���Ϊʲô��ʮ�ְ��������÷ֱ�ƥ����DNA�е����ּ����A��G��C��T���ĸ���ԭ������������£������˶����Դ���������ڹ������ƥ��Ĺ���[2-4]��Ȼ����ʮ���ȥ�ˣ��ź�����һֱ��δ��ȡ��ͻ���ԵĽ�չ�����������21����֮�ʣ�Watson�����ƥ�������Ȼ����δ�õ�ڹ�͵�������ѧ���ش�����֮һ�������й��˾���û�еõ���ŵ���������������й�Զ�š��Ƶ��ھ�������ѧ˵������̫�����Լ���ʮ���ԣ��ĵ�����ѧ�ں������ۣ�ʹ������ŵ������յĽ�����
��
�����ӡ��Ƶ��ھ�������ѧ˵��DNA���ּ���������ԣ�
���Ƶ��ھ�������ѧ˵��������һ����Ȼ��������д�����֣�
����֮����++��
����֮����+-��
����֮����--��
����֮����-+��
�ھ���ֲ����С�����֮�С��ĵ����֣��ʳ�֮Ϊ����ѧ˵��
һ��������Ļ��������ּ��������DNA,RNA��
���Ǵ����ּ���ṹ�ĵ�ɷֲ���������������ʵ��
��
��Щ���ּ����һ��ͬ���������ã��γ�������ա�����������ѧ�������Щ���ӵ��γ��Լ���һ����Ϊ��������DNA,RNAʱ�������ڵ�һ���������ݱ仯�����е���������Դ�������������Ĵ����á�
������������ѧ����������ѧ��ָ������Զ��������ԭʼ����ѧ������ڿ�ʼ���й����ֺ�����Ͱ�����ͨ���������ụ�����ӵĸ����Ͷ�Ԫ������ӣ���˫��ۺϷ�Ӧ������RNA����Ӧ�ĵ����壬����RNAת��Ϊ�����ȶ�����������DNA���Ӵ����ﵰ���ʵĺϳɵ�;�����Ϊ����DNA�����Ƴ�t-RNA������������ְ�����ִ�DNA���Ƴ�m-RNA��������t-RNA���ṩ�İ����ᣬ�ϳɳ�������صĵ����ʡ����Դ�ԭʼ�����ġ���ѧ�������������ڡ����м����������������е������������������ˡ�����������ϣ����Ǻ�����������в��������Ļ���ģʽ��������������Դ��ʼ�����������������ã�
��
��
���������������ѧ�У�����RNA��DNA�����������߹�ϵ����֮Ϊ�����ķ��������ź����Ǻ����ᵽ��������Դ�Ĵ�����������ã���ʵ��������Ҫ�������������أ�����ʵ��ϸ������DNA��Χ�кܶ�ܶ���������������Դ��ˮ������ӣ������ڲ�ͬ��ϸ����������ڲ�ͬ��ϸ��������������Դ�ķֲ���ͬ�������Ż���IJ�ͬ���ܡ�
��
���������й��Ŵ�̫����ʮ����ͼ�����t-RNA������
������ѡ���Եĵ�����ѧ�ں�
��
3.1 t-RNA�������ӺͰ�������64�Զ�Ӧ��ϵ
������������Ƽ��ķ�չ�����Ƕ����뷢�ֵ����������Ĵ��ڣ���Щѧ����Ϊ�������������Ӧ�û�������֮����������������࣬�����е�ѧ����Ϊ���������棬�����ϵ����࣬���»���Ψһ�ġ������൱�̶����ɺ�һ�ֿ�����������Ϊ�����ij��֣��ر�������ij��֣��������Ļ�ѧ�ݻ����̾��зdz�����Ĺ��ɣ�����Ҫ��ѭ�й��Ŵ�̫�����Լ������ŵ���ʮ���ԵĹ��ɡ����������������ǵĻ�ѧ�ݻ������뻷���Ƿ����������Ĺ�����֧�䣿�������ǵĻ�ѧ�����������е��������������������������������Ҫ�ĺ������ʣ�DNA�͵������������ϵģ��Ϳ���������������������һ���Ƕ�ô�ѵ����飡
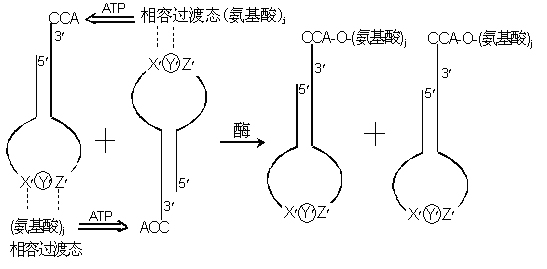
�����һ��̽����δ�DNA��RNA��������Ĺ��̣�Ӧ������ָ�������������У�Ϊ��ʹRNA�ϳɵ����壬�����ɸ��ֲ�ͬ�ṹ��t-RNA��ͨ���������巴�����ӣ���ʶ��ͬ�����ᣬ�γ��м������ṹ������ʹ��ͬ������������ͬ�ṹ��t��RNA��3¢ĩ�ˣ�CCA�ϣ�Ȼ���ٰ���m-RNA��Ҫ���ں������ڰ�����ѻ����������ӵ����������ϣ��ɼ�m-RNA��t-RNA������֮�������ж�Ӧ��ϵ��
��
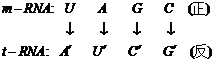
������m-RNA���������ӣ�![]() ��
��
![]() ������
������
![]()
![]()
![]()
![]()
t-RNA�ķ������ӣ�![]() ��
��![]() ������
������![]()
�����ɵ������йط������ӺͰ������Ӧ��ϵ��Watson��Table������2����
��
��2 ��t-RNA�������뷴���������ļ��֮���γɵ�Watson��Table
|
t-RNA �������� |
���ݰ����� |
t-RNA �������� |
���ݰ����� |
t-RNA �������� |
���ݰ����� |
t-RNA �������� |
���ݰ����� |
||
|
3¢��5¢ |
3¢��5¢ |
3¢��5¢ |
3¢��5¢ |
||||||
|
A�� eq \o\ac(��,A')A'A�� A�� eq \o\ac(��,A')A'G�� |
Phe,F |
A�� eq \o\ac(��,G')G'A�� A�� eq \o\ac(��,G')G'G�� A�� eq \o\ac(��,G')G'U�� A�� eq \o\ac(��,G')G'C�� |
Ser,S |
A�� eq \o\ac(��,U')U'A�� A�� eq \o\ac(��,U')U'G�� |
Tyr,Y |
A�� eq \o\ac(��,C')C'A�� A�� eq \o\ac(��,C')C'G�� |
Cys,C |
||
|
A�� eq \o\ac(��,A')A'U�� A�� eq \o\ac(��,A')A'C�� |
Leu,L |
A�� eq \o\ac(��,U')U'U�� A�� eq \o\ac(��,U')U'C�� |
�� ,Y ��ֹ |
A�� eq \o\ac(��,C')C'U�� A�� eq \o\ac(��,C')C'C�� |
�� ,W ��ֹ |
||||
|
G�� eq \o\ac(��,A')A'A�� G�� eq \o\ac(��,A')A'G�� G�� eq \o\ac(��,A')A'U�� G�� eq \o\ac(��,A')A'C�� |
Leu,L |
G�� eq \o\ac(��,G')G'A�� G�� eq \o\ac(��,G')G'G�� G�� eq \o\ac(��,G')G'U�� G�� eq \o\ac(��,G')G'C�� |
Pro,P |
G�� eq \o\ac(��,U')U'A�� G�� eq \o\ac(��,U')U'G�� |
His,H |
G�� eq \o\ac(��,C')C'A�� G�� eq \o\ac(��,C')C'G�� G�� eq \o\ac(��,C')C'U�� G�� eq \o\ac(��,C')C'C�� |
Arg,R |
||
|
G�� eq \o\ac(��,U')U'U�� G�� eq \o\ac(��,U')U'G�� |
Gln,Q |
||||||||
|
U�� eq \o\ac(��,A')A'A�� U�� eq \o\ac(��,A')A'G�� U�� eq \o\ac(��,A')A'U�� |
Ile,I |
U�� eq \o\ac(��,G')G'A�� U�� eq \o\ac(��,G')G'G�� U�� eq \o\ac(��,G')G'U�� U�� eq \o\ac(��,G')G'C�� |
Thr,T |
U�� eq \o\ac(��,U')U'A�� U�� eq \o\ac(��,U')U'G�� |
Asn,N |
U�� eq \o\ac(��,C')C'A�� U�� eq \o\ac(��,C')C'G�� |
Ser,S |
||
|
U�� eq \o\ac(��,A')A'C�� |
�� ,M ��ʼ |
U�� eq \o\ac(��,U')U'U�� U�� eq \o\ac(��,U')U'C�� |
Lys,K |
U�� eq \o\ac(��,C')C'U�� U�� eq \o\ac(��,C')C'C�� |
Arg,S |
||||
|
C�� eq \o\ac(��,A')A'A�� C�� eq \o\ac(��,A')A'G�� C�� eq \o\ac(��,A')A'U�� C�� eq \o\ac(��,A')A'C�� |
Val,V |
C�� eq \o\ac(��,G')G'A�� C�� eq \o\ac(��,G')G'G�� C�� eq \o\ac(��,G')G'U�� C�� eq \o\ac(��,G')G'C�� |
Ala,A |
C�� eq \o\ac(��,U')U'A�� C�� eq \o\ac(��,U')U'G�� |
Asp,D |
C�� eq \o\ac(��,C')C'A�� C�� eq \o\ac(��,C')C'G�� A�� eq \o\ac(��,C')C'U�� C�� eq \o\ac(��,C')C'C�� |
Gly,G |
||
|
C�� eq \o\ac(��,U')U'U�� C�� eq \o\ac(��,U')U'C�� |
Glu,E |
||||||||
|
�� |
�� |
�� |
�� |
�� |
�� |
�� |
�� |
||
��
�ɱ�2���Կ���������64�������ӣ���ÿһ�������Ӷ������������� eq \o\ac(��,Y)Y�������ļ�� eq \o\ac(��,A')A'ʱֻ�����ְ�����ƥ�䣻 eq \o\ac(��,G')G'ֻ�����ְ�����ƥ�䣻C¢��ֻ�����ְ�����ƥ�䣻��U¢ֻ�����ְ�����ƥ�䡣Ϊʲô��������ƥ���ϵ�أ������������������ﻯѧҲ���ش�����⡣
�����й����Ŀ���������һ������ͳһ�������͵�ʵ�����Ұ�һ���������������γ���ά����ռ��ԭ�����������γ�64�������������ӣ�
��
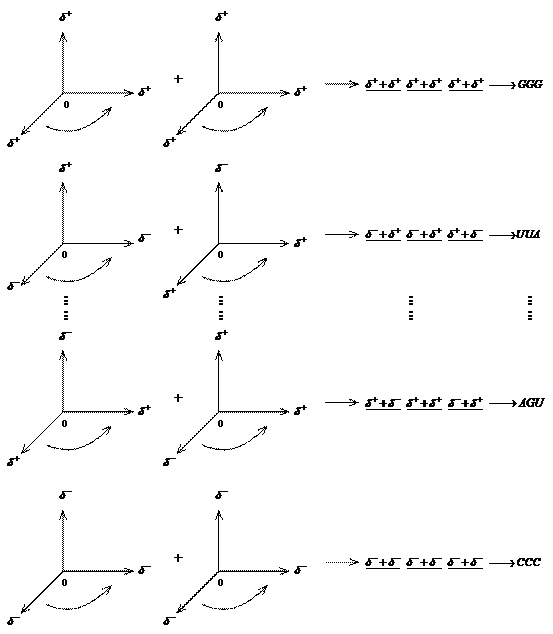
��
�ɴ˿ɵ����н����
��
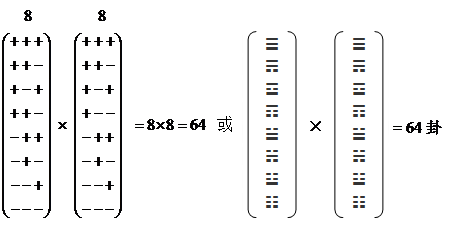
��
����64�������������ӡ�
����������£����й��Ŵ���ʮ����ͼ�οɵ�����������ͬ����ͬ�İ�����ķֲ�ͼ����ͼ1����
��
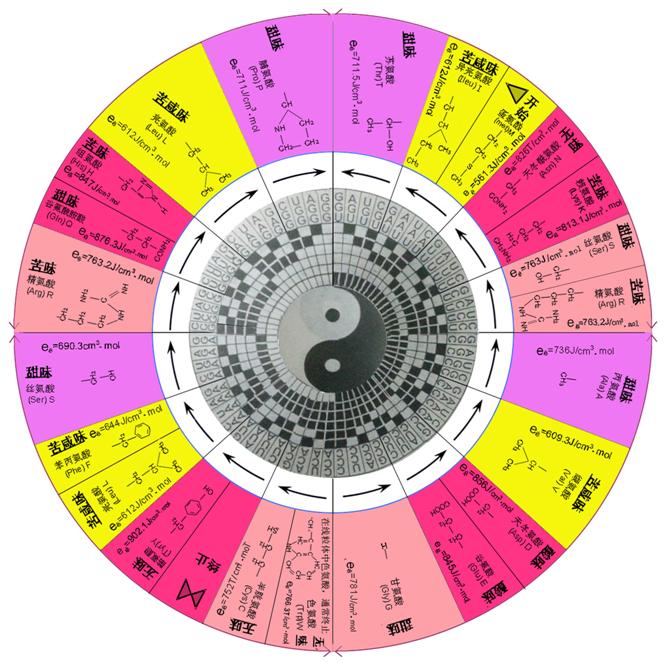
��
* ��ͼ�����������Ӿ�Ϊ�������ӣ���x¢y¢z¢��
ͼ1 �й�64�Զ�t-RNA�������ӺͰ������ϵ��ȫϢͼ
��
���Ͽ��Կ������й��Ŵ�����ͼ�dz��й��ɵ������˶�ʮ�ְ�������t-RNA�������ӱ仯��ȫϢ��ϵ�����������м����棺
��1����ͼ1���Կ�����20�ְ�����ֳ��Ĵ������Կ���̫���������ӵ�һ���Ϊ����ֳ��Ĵ�����ÿ�����к���ϡ��ơ�����
��

��
����G����5�ְ����ᣨP��L��H��Q�� eq \o\ac(��,R)R��
A����6�ְ����ᣨ eq \o\ac(��,S)S��F��L��Y��C��W��
C����5�ְ����ᣨG��E��D��V��A��
U����7�ְ����ᣨ eq \o\ac(��,R)R�� eq \o\ac(��,S)S��K��N��M��I��
���о����ᣨR����˿���ᣨS���������Σ�����ʮ�ְ����ᡣ�ɴ˿�֪t-RNA�������ӣ�X¢ eq \o\ac(��,Y)Y¢Z¢���ĵ�һ���X¢�ǽ��ɲ�ͬ���������������Ҫ�ż���
��2����ͼ1�п��Կ������dz����ص������Ǿ���ÿ�����ﶼ����ͬ�������ӣ�X¢ eq \o\ac(��,Y)Y¢Z¢�����ļ�� eq \o\ac(��,Y)Y¢֮��ɫ��Ϊ��ͬ��
�磺 eq \o\ac(��,G)G¢ eq \o\ac(��,A)A¢ eq \o\ac(��,C)C¢ eq \o\ac(��,U)U¢
����ɫ�� ����ɫ�� ����ɫ�� ����ɫ��
�ɴ˿��Կ�����t-RNA�������ӣ�X¢ eq \o\ac(��,Y)Y¢Z¢�������ļ�� eq \o\ac(��,Y)Y¢�ֱ��һ�ఱ���ᣬ���൱�߶ȵ�ѡ���ԡ���˵���й��Ŵ����Ե�Ԥ���뵱���������ﻯѧ�Ľ�������ȫһ�µġ�
��3����ͼ1�����Կ�����t-RNA�������ӵĵ��������˳����ͼ������Ϊ�����������![]() ����������ʽ�����Ҳ�����
����������ʽ�����Ҳ�����![]() ���������ҷ�ʽ��
���������ҷ�ʽ��
����Ϊʲôt-RNA�����������ļ���� eq \o\ac(��,Y)Y¢������������ôͻ����ѡ�������⣬������ԭ��������ǰ�˵������в����������˱��ĵ���ҪĿ�ľ����״����ھ����ܶȵĶ����ķ������������еĿ�ѧ�ں���
��
3.2 �״η���t-RNA�����������ļ�� eq \o\ac(��,Y)Y���ھ����ܶȾ����������ѡ����
�Դӷ��������백����֮���Watson��������������һֱ��˼����Ϊʲô��������ѡ���ԣ�����˸��ֹ۵㣬��Ҫ���������㣺һ����Ϊt-RNA��״�ṹ��ijЩ���ο��ܶԲ�ͬ���������ѡ���ԣ����ɡ��������ӡ������ã�����ʵ���ϸ㲻�����һ��������Ϊ��һ�����صĻ�ѧ����ø��t-RNA�ṩ�������ѡ���ԡ����Ǿ�����ʲô�أ�����û�����ṩʵ�塣�����ֿ���֮�ʣ����������״γɹ��ط�����t-RNA�ķ������ӱ������������ļ�� eq \o\ac(��,Y)Y�����ఱ�����ھ����ܶȻ�ѧ��Ϣ��֮�������еĹ�ϵ����������Ĺ�������ȡ���ڷ����������ļ���Ͱ������ھ����ܶȻ�ѧ��Ϣ����С�������ϡ�
3.2.1 ���ӻ�ѧ��ͷ����֮ʧ�����ھ����ܶȻ�ѧ�ṹ��Ϣ����������
������70�����Van Krevlen����������ھ����ܶȸ������㷽��[9��10]���������������жϲ�ͬ���Ӽ��������Լ����۷�Ӧ�о����ʺ͵����ھ����ܶ�֮��Ķ�����ϵ[5-8]�����ߴ��п������ھ����ܶȵĸ��������ż������������Ҫ�����ӻ�ѧ��ͷ���㷽����Խ�����������Ϊ��һ�����ܿ��˷��Ӽ������������ r5~6 �ɷ��ȵ�����[4]��
��ѭEinstein�����ԡ�Ҫ����һ���Ƕ��������⡱�Ľ̵������߷�����ǰ�ھ����ܶȸ���dz��ɹ��ؽ����˰�������������������ּ��֮���ƥ���ϵ�������ھ����ܶȵĶ������ݣ��ɰ��������ԭ����������ֳ��Ĵ��࣬���������ھ����ܶȽ����˱Ƚϣ���������֮���ƥ���ϵ��Watson��s Table �������������һ���ԡ�
������֪���ǹ��ۼ�����������������Ӽ��ձ���ڵ�ɫɢ�����ԣ������յ����ԣ�����������������������˽����ӵĽṹ������õĻ���������Щ�ṹ���������ͨ�����������õ��ھ����ܶȻ�ѧ��Ϣ���������ġ�����Van Krevlen����ļ����ھ����ܶȷ�ʽ[9��10]�����Էֱ�õ�ɫɢ�������������������ص��ھ����ܶȵļ��㹫ʽ��ʽ1-3����
|
|

����Fd��Fp��Fh�ֱ�Ϊ���ŵ�ɫɢ�����ԡ����������������VΪ�˷�����������ɻ��Ż�ԭ�ӹ�������ӺͶ��õ���
�����������㹫ʽ���ɷֱ�����Ŵ��������еĸ�������ھ����ܶ��Լ����ఱ������ھ����ܶȣ�Ȼ�����ǿ��Խ�һ���ӷ��ӽṹ�Ļ�ѧ�Ƕ���ȫ���ڹ�ͼ�����ԭ���Լ������ʺϳɹ����а������������巴�����ӵڶ����֮����ڸ�ѡ���Ե����⡣
3.2.2 ���ھ����ܶȿ������백����֮�䶨����ϵ����ʾ������˵�����ص����ԭ��
�����������㹫ʽ�����ȼ��������ּ����A��T��G��C��U���Ŀ˷���������ɸ��������������������ھ����ܶ��Լ������ھ����ܶ�֮�ܺͣ�![]() �����ܽ����
�����ܽ����![]() ���������ڱ�3�С�
���������ڱ�3�С�
��
��3 ���ּ���ھ����ܶ�e��J/cm3��mol�����˷������L��cm3/mol��
|
��� |
|
|
|
|
|
V |
|
T |
394 |
272 |
146 |
812 |
284 |
82.8 |
|
U |
348 |
335 |
167 |
850 |
29.2 |
72.3 |
|
A |
355�������� 434��˫���� |
69 |
139 |
563�������� 642��˫���� |
23.8 25.4 |
96.5 |
|
C |
365 |
204 |
198 |
767 |
27.7 |
77.9 |
|
G |
335�������� 407��˫���� |
127 |
185 |
647�������� 719��˫���� |
25.5 26.8 |
100 |
��
�ӱ�3���Կ������м�����ھ����ܶȶ�����ed > ep > eh���ص㡣�����3��ָA��G�ֱ��е�����˫��ֵ�����е�������������йأ���˫����DZ�������ھ����ܶ��йأ����������������ᣨ�����ᣩ�����ڹ��۷�Ӧǰ�������̬�Ŀ��ۺ������йء����ǵ��������ԵĶ�����ϵ���ɿ�����eT��eU���ܽ�Ȳ�����T=28.4����U=29.2����С������m-RNA�ж���U����ʽ���֣��ʲ���T����ͬ����Van Krevlen��ʽ�ķ������ֱ���������а�������ھ����ܶȣ����г���T(U)��A��G��C���ʱ����������X��Y��Z�������ļ����Y�������ھ����ܶȣ�����4~��7��
��4 ��m-RNA�����ӵڶ����U��t-RNA��������A����صİ�������ھ����ܶ�(J/cm3.mol)
|
t-RNA�������� ���ļ��Y¢ |
HOOC��CH��NH2 R��Ϊ�Ǽ��Եģ���ˮ�Ի��ţ� | ���� eq \o\ac(��,X)XָDNA�������еĵڶ������ R X�� ָt-RNA���������еĵڶ������ |
||||||
|
A��
|
�� �� ������ |
C eq \o\ac(��,A)A�� |
G eq \o\ac(��,A)A�� |
U eq \o\ac(��,A)A�� |
A eq \o\ac(��,A)A�� |
U eq \o\ac(��,A)A��C |
|
|
������ |
�Ӱ��� Val.V |
������ Leu.L |
�������� Ile.I |
�������� Phe.F |
������ Met.M |
||
|
|
355 |
|
386.6 |
417 |
417 |
475 |
387 |
|
|
69 |
|
20.4 |
17.0 |
17.0 |
13.2 |
13.3 |
|
|
139 |
|
203 |
183 |
180 |
154 |
160 |
|
|
642 (25.4) |
|
609 (24.6) |
612.9 (24.8) |
612.9 (24.8) |
642.2 (25.4) |
561.3 (23.8) |
|
|
|
|
|
|
|
||
��
����
��ָ�ܽ�Ȳ�����=![]() ֵ��
ֵ��
�ɱ�4���Կ��������������ļ��A¢���ܵ��ھ����ܶȣ�![]() �������ְ������ܵ��ھ����ܶȣ�
�������ְ������ܵ��ھ����ܶȣ�![]() �����dz�������������ְ������뷴���������ļ��
eq \o\ac(��,A)A¢��ƥ�䣬Ҳ������������T(U)����йء�
�����dz�������������ְ������뷴���������ļ��
eq \o\ac(��,A)A¢��ƥ�䣬Ҳ������������T(U)����йء�
��
��5 ��m-RNA�����ӵڶ����������G��t-RNA��������C����صİ������ھ����ܶ�(J/cm3.mol)
|
t-RNA�������� ���ļ��Y¢ |
HOOC��CH��NH2 R �����ܹ��γɸ�������Եİ����� | R |
||||||
|
eq \o\ac(��,C')C' |
�� �� ������ |
A eq \o\ac(��,C)C��U ����ֹ�� |
G eq \o\ac(��,C)C��
U eq \o\ac(��,C)C�� |
C eq \o\ac(��,C)C�� |
U eq \o\ac(��,C)C�� |
A eq \o\ac(��,C)C�� |
|
|
������ |
ɫ���� Trp.W |
������ Arg.R |
�ʰ��� Gly.G |
˿���� Ser.S |
���װ��� Cys.C |
||
|
|
365 |
|
572 |
510 |
500 |
400 |
355 |
|
|
204 |
|
19.3 |
78.5 |
75 |
92.5 |
38.2 |
|
|
198 |
|
175 |
174* |
206* |
271* |
359 |
|
|
767 (27.7) |
|
766.3 (27.6) |
763.5 (27.5) |
781 (28.0) |
763.5 (27.5) |
752.2 (27.4) |
|
|
|
|
|
|
|
||
��
ע *ָ�ѿ۳�����������ھ����ܶ�ֵ��
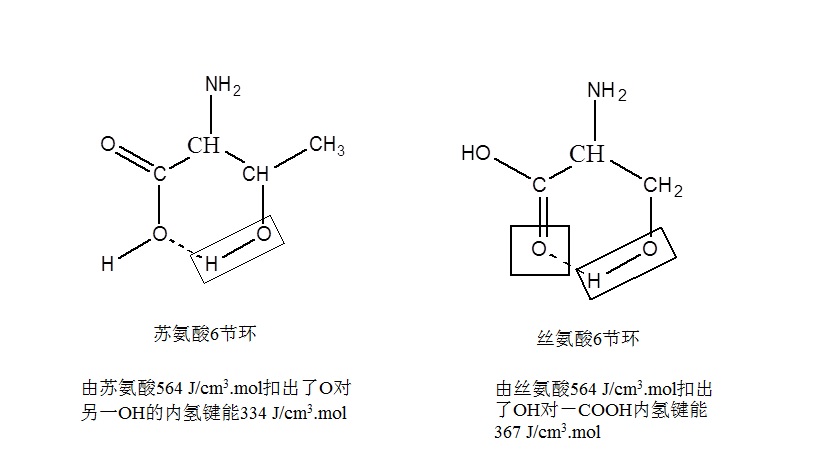
������ױ��������иʰ��ᡢ˿���ᡢ����������ˮ�����£������γɷ�������������ڼ����ھ����ܶ�ʱӦ�۳���������������ܣ����磺
��
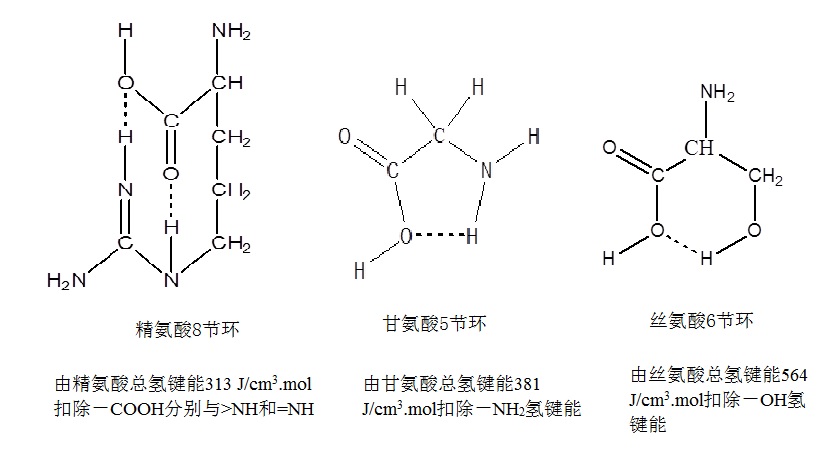 |
��֮�ӱ�5����һ�ο��Կ��������������ļ��
eq \o\ac(��,C)C¢��![]() �����ְ������
�����ְ������![]() Ҳ�൱�ӽ����������ְ�������
eq \o\ac(��,C)C¢��ƥ�䡣
Ҳ�൱�ӽ����������ְ�������
eq \o\ac(��,C)C¢��ƥ�䡣